
👋 About Me
Hi! I’m Wenxi Chen (陈文熙), a first-year Ph.D. student at Shanghai Jiao Tong University and Shanghai Innovation Institute. I am a member of the X-Lance Lab, advised by Prof. Xie Chen. I received my Bachelor’s degree in Computer Science from the IEEE Pilot Class at SJTU in 2025.
My research focuses on understanding, generation, and interaction across general audio (including speech, audio, and music), as well as multimodal large language models. My recent work spans speech representation modeling (SSL and codecs), audio understanding, zero-shot TTS, end-to-end spoken dialogue systems, and general music editing.
📝 Publications
For the most up-to-date publication list, please visit my Google Scholar profile. (* indicates equal contribution)
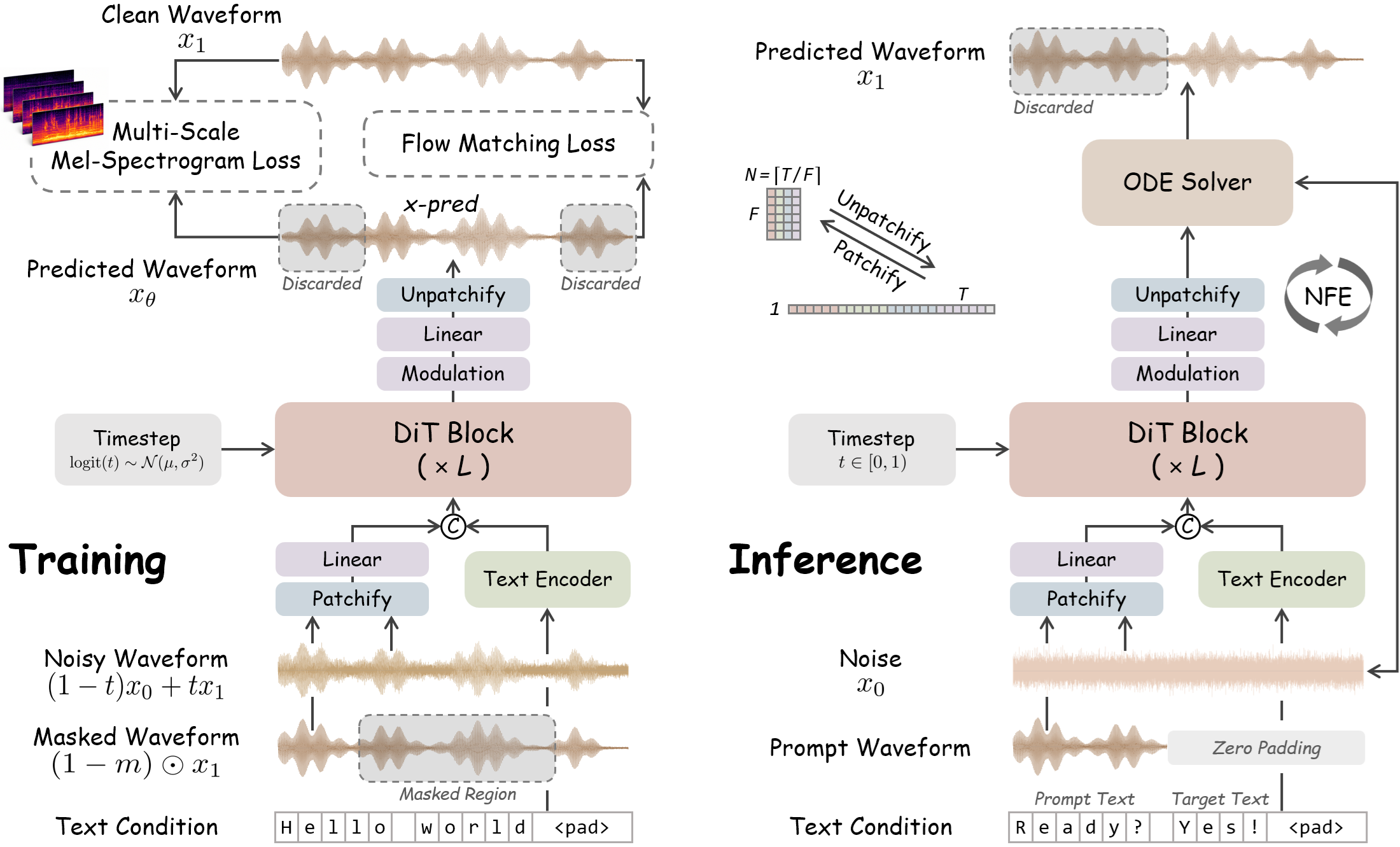
WavTTS: Towards High-Quality Zero-Shot TTS via Direct Raw Waveform Modeling
Wenxi Chen, Dongya Jia, Yushen Chen, Zhikang Niu, Yuzhe Liang, Xiquan Li, Ruiqi Yan, Ziyang Ma, Guanrou Yang, Sanyuan Chen, Yue Wang, Zhuo Chen, Kai Yu, Xie Chen

- An exploration of an end-to-end zero-shot TTS system that directly models speech in the native raw waveform space.
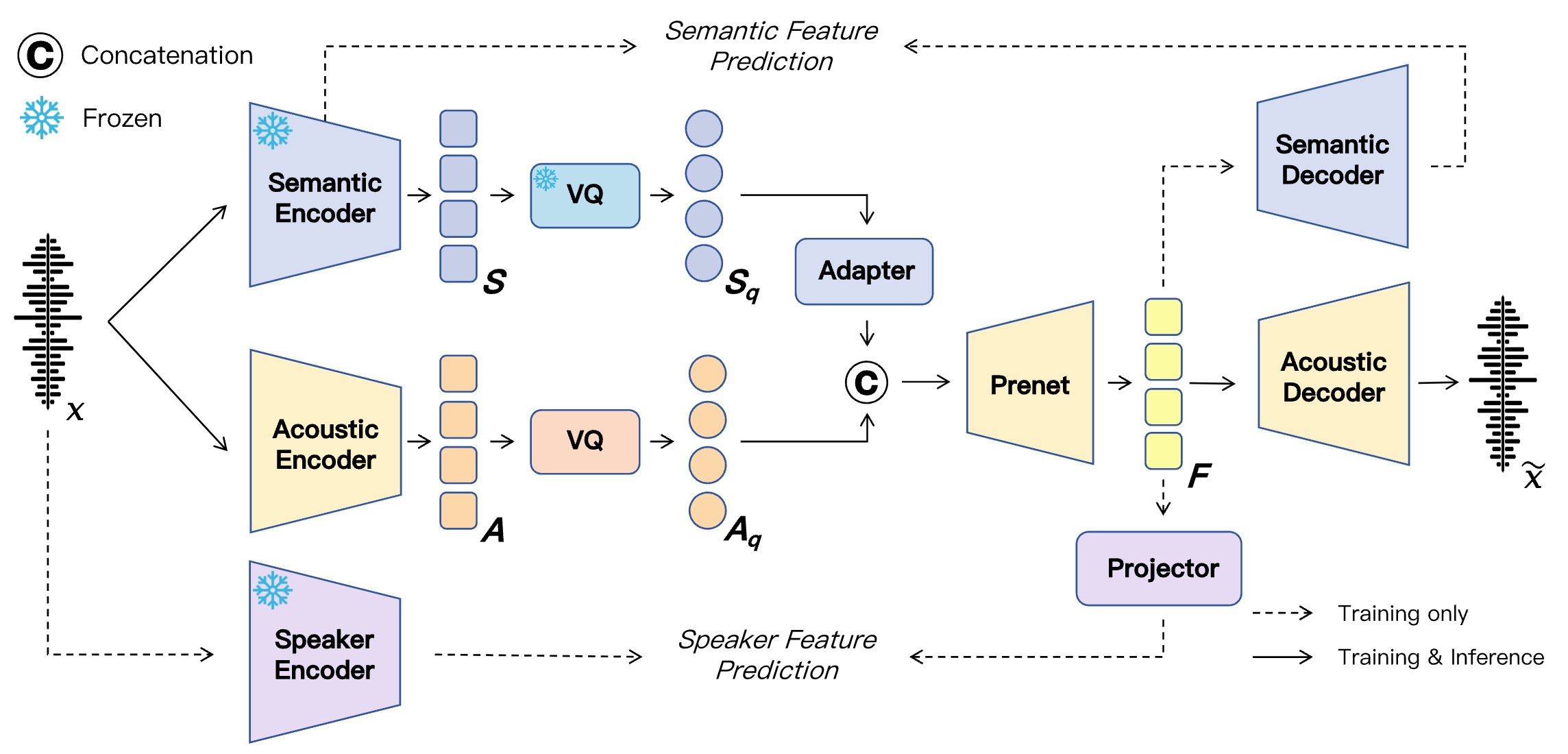
SAC: Neural Speech Codec with Semantic-Acoustic Dual-Stream Quantization
Wenxi Chen, Xinsheng Wang, Ruiqi Yan, Yushen Chen, Zhikang Niu, Ziyang Ma, Xiquan Li, Yuzhe Liang, Hanlin Wen, Shunshun Yin, Ming Tao, Xie Chen

- A dual-stream speech codec that achieves both high-quality reconstruction and rich semantic representations for advanced speech generation.
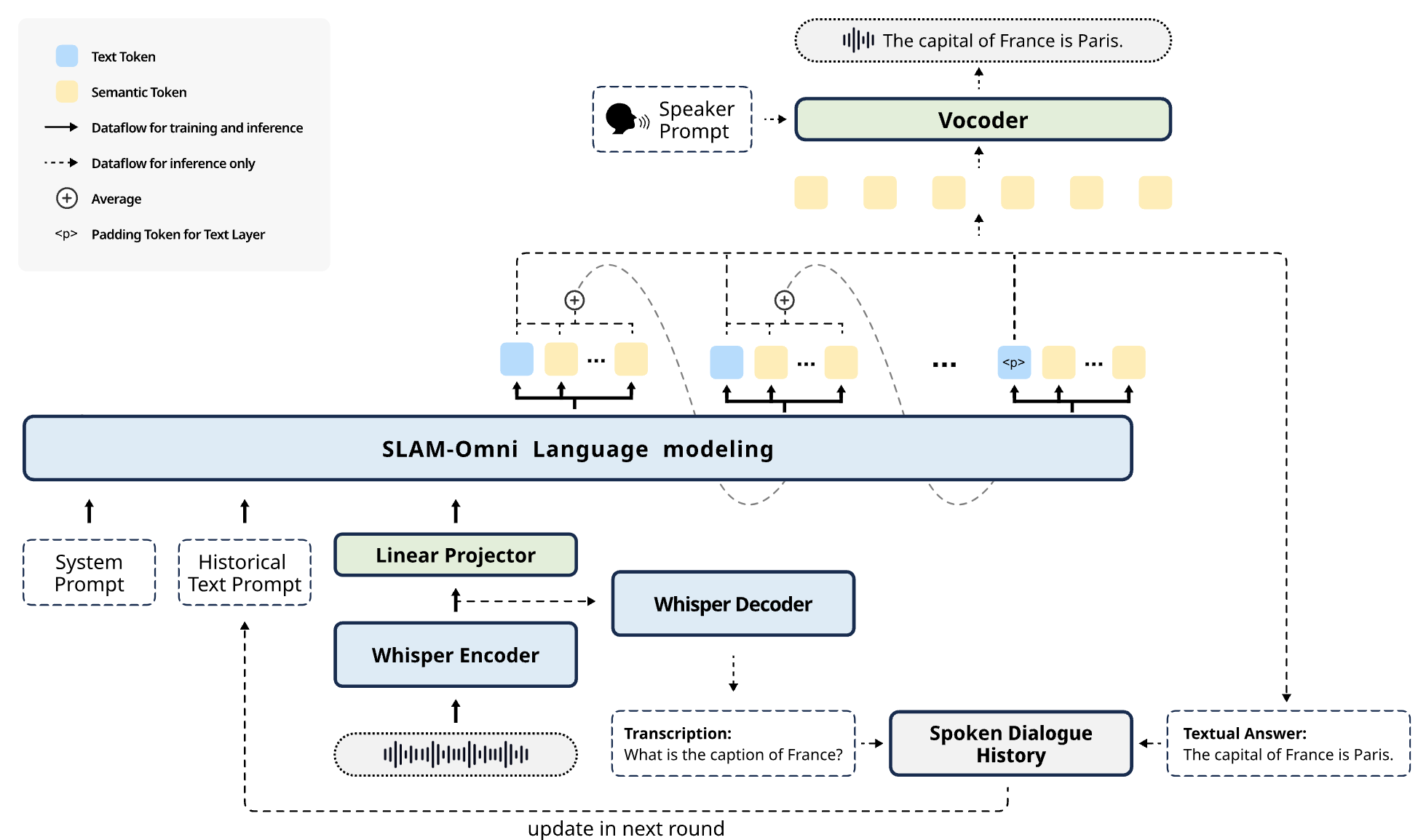
SLAM-Omni: Timbre-Controllable Voice Interaction System with Single-Stage Training
Wenxi Chen, Ziyang Ma, Ruiqi Yan, Yuzhe Liang, Xiquan Li, Ruiyang Xu, Zhikang Niu, Yanqiao Zhu, Yifan Yang, Zhanxun Liu, Kai Yu, Yuxuan Hu, Jinyu Li, Yan Lu, Shujie Liu, Xie Chen

- A high-efficiency, end-to-end voice interaction system that enables zero-shot timbre control and accelerated inference.
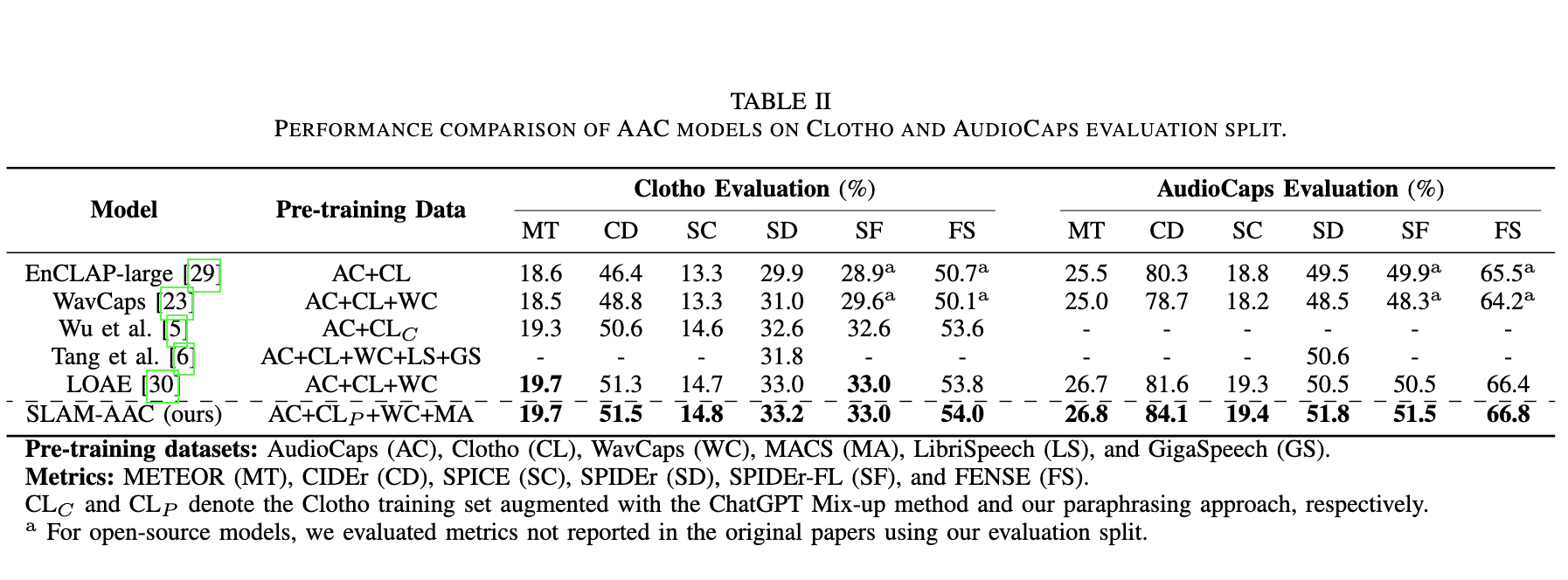
SLAM-AAC: Enhancing Audio Captioning with Paraphrasing Augmentation and CLAP-Refine through LLMs
Wenxi Chen*, Ziyang Ma*, Xiquan Li, Xuenan Xu, Yuzhe Liang, Zhisheng Zheng, Kai Yu, Xie Chen
- Enhancing audio captioning through paraphrasing-based data augmentation and a plug-and-play CLAP-based rescoring strategy for LLM-driven generation.
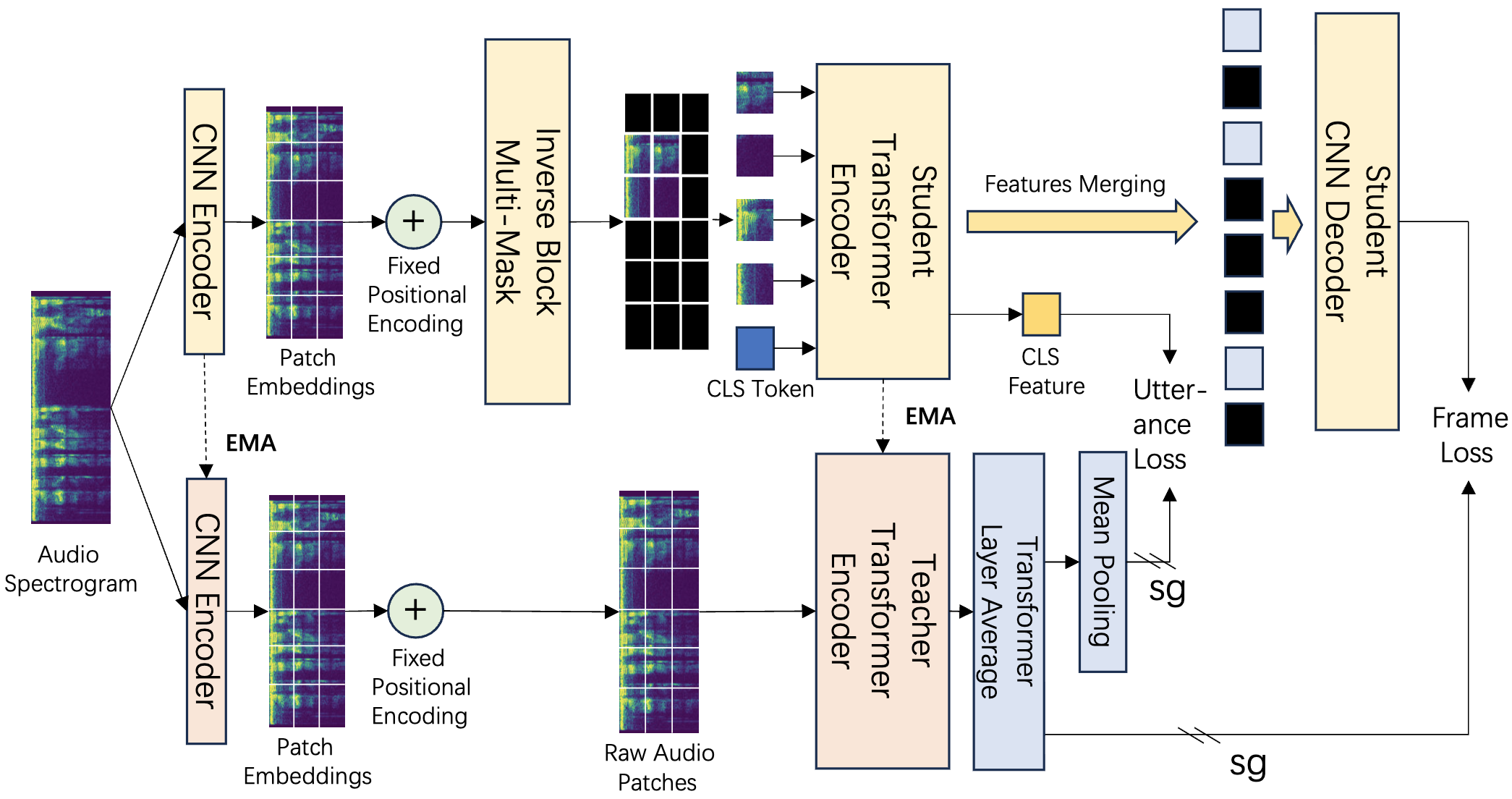
EAT: Self-Supervised Pre-Training with Efficient Audio Transformer
Wenxi Chen, Yuzhe Liang, Ziyang Ma, Zhisheng Zheng, Xie Chen

- An audio self-supervised learning model achieving superior representational performance with extreme pre-training efficiency.
- EAT have surpassed 1M total model downloads on Hugging Face!
ACL 2025 MainSimulS2S-LLM: Unlocking Simultaneous Inference of Speech LLMs for Speech-to-Speech Translation, Keqi Deng, Wenxi Chen, Xie Chen, Phil Woodland.EMNLP 2025 FindingsURO-Bench: Towards Comprehensive Evaluation for End-to-End Spoken Dialogue Models, Ruiqi Yan, Xiquan Li, Wenxi Chen, Zhikang Niu, Chen Yang, Ziyang Ma, Kai Yu, Xie Chen.ICASSP 2025 OralDRCap: Decoding CLAP Latents with Retrieval-augmented Generation for Zero-shot Audio Captioning, Xiquan Li, Wenxi Chen, Ziyang Ma, Xuenan Xu, Yuzhe Liang, Zhisheng Zheng, Qiuqiang Kong, Xie Chen.
🎖 Honors and Awards
- Rongchang Science and Technology Innovation Scholarship, 2024-2025
📖 Educations
- 2025.09 - Present, Ph.D. in Computer Science, X-Lance Lab, Shanghai Jiao Tong University, Shanghai.
- 2021.09 - 2025.06, B.Eng. in Computer Science (IEEE Pilot Class), Shanghai Jiao Tong University, Shanghai.
💻 Internships
- 2025.12 - Present, ByteDance, Seed Speech Team, Shanghai, China. Co-advised by Dongya Jia and Zhuo Chen.
- 2025.07 - 2025.12, Soul App, Multimodal Interaction Group, Shanghai, China. Advised by Xinsheng Wang.
- 2024.09 - 2025.06, Microsoft Research Asia, Speech Team, Beijing, China. Co-advised by Shujie Liu and Jinyu Li.
🏆 Competition
- IEEE ICME 2024 Challenge Semi-supervised Acoustic Scene Classification under Domain Shift - Ranked 2nd, Team Leader
- DCASE Challenge 2024 Task 6: Automated Audio Captioning - Ranked 3rd, Team Leader